CISA Vulnrichment¶
Overview
An incorrect CWE assignment caught my eye while reading a post
I was reading a post on LinkedIn and the CWE assigned by CISA ADP looked wrong so...
- I used my NotebookLM CWE notebook, and other LLMs, to determine the appropriate CWE.
- I then raised an issue: https://github.com/cisagov/vulnrichment/issues/84.
- I then decided to dig a bit more into this... specifically the CWEs assigned by CISA ADP.
Using LLMs to find incorrect CWE assignments at scale
I used langchain to create a consensus of LLMs to review all CWEs assigned by CISA ADP to find issues:
- These issues were found automatically by a consensus of 3 LLMs: (current state-of-the-art) ChatGPT4o, Gemini 1.5 Pro, Claude 3.5 Sonnet who were asked to review CWEs assigned to CVEs by CISA ADP.
-
The consensus output was then reviewed by a human (me).
-
I created 3 Vulnrichment Github Issues initially and these were accepted by CISA Vulnrichment and resolved promptly!
-
I then provided a report to CISA Vulnrichment for all CWEs that were incorrect based on the consensus.
Using LLMs to assign correct CWEs
Finally, I showed how NotebookLM can be used for CWE assignment
- It avoids the problem of
- training language models on bad data (existing CVE CWE assignments)
- training humans on the detailed CWE standard (though a basic understanding is still required)
- NotebookLM did well in recommending a CWE given a CVE Description.... and providing a supporting CVE from the CWE Observed Examples in the CWE standard.
- NotebookLM has a large context window which allows it to digest the large CWE standard, and it is source-grounded as described in the NotebookLM chapter.
- Notebook on CWEs describes how to create this NotebookLM for CWEs
The different approaches used (and the subscription plan used):
- code:
- ChatGPT4o OpenAI Batch API (Plus Plan)
- langchain calling 2 LLMs via APIs: Gemini 1.5 Pro, Claude 3.5 Sonnet (ChatGPT4 or ChatGPT4o is also supported in the code (but commented out) if your plan supports that)
- no-code using the browser chat interface is not shown here but it is useful for initial evaluation
- Gemini 1.5 Pro (subscription)
- Claude 3.5 Sonnet (prepay)
Success
The approach described here resulted in successfully identifying incorrectly assigned CWEs, and identifying the correct CWEs, and a report to CISA Vulnrichment.
Consensus of 3 LLMs¶

Source Code
CISA Vulnrichment¶
Quote
The CISA Vulnrichment project is the public repository of CISA's enrichment of public CVE records through CISA's ADP (Authorized Data Publisher) container. In this phase of the project, CISA is assessing new and recent CVEs and adding key SSVC decision points. Once scored, some higher-risk CVEs will also receive enrichment of CWE, CVSS, and CPE data points, where possible.
I have great admiration for CISA and their pragmatic initiatives like CISA KEV and SSVC and have spoken about them and applied them in production.
Tip
One of the many benefits of this Vulnrichment project is that feedback can be provided as GitHub issues and the team is VERY responsive ✅  🙌
🙌
- The 'Bug' label was assigned the same day to the 3 issues I submitted: https://github.com/cisagov/vulnrichment/issues?q=is%3Aissue+author%3ACrashedmind+is%3Aclosed.
- The changes were accepted and applied the next working day and a comment was added to the ticket which was then closed.
My overall goal here was to
- Show that LLMs could augment human analysts where vulnerability enrichment today is largely done manually.
- Show how to use them for this purpose.
- Get people to use LLMs to improve the quality of the CVE data in general, and in this specific example case, the CWE data.
- Maximize the value of the CISA ADP data and enrichment by improving CWE-assignment quality.
Get CVEs Enriched by CISA ADP¶
What to ask the LLMs?¶
Different approaches are possible when providing the CVE Description to the LLM:
- provide the CWE assigned as part of the CVE, and ask the LLM if it agrees or not, and only if not, why
- This reduces the output token count/cost by only outputting the verbose rationale in case of disagreement
- ask the LLM to assign one or more CWEs, with rationale
The first approach is easier and simpler and cheaper (in terms of token use i.e. shorter response output), and better as a first pass option to get the low hanging fruit.
The second approach could be used at the time of CWE assignment to get a second opinion.
Consensus¶
To minimize human effort, 3 LLMs are used and the consensus is reviewed
- The LLMs are state-of-the-art models from different providers i.e. the best available and reasonably independent.
- The results are sorted by consensus i.e. 3 models in agreement, then 2 models in agreement,.... and by the LLM's confidence in their responses
- A Human (me) then reviewed (sorted by consensus and confidence) and made the final decision.
Recipe¶
- Get the Vulnrichment subset of CVEs where CISA ADP assigned a CWE (regardless of whether the CWE was the same or different than that assigned by the CNA) into a sheet/CSV file.
- ~1.8K (CISA ADP Assigned CWEs) of ~~10K CVEs (in Vulnrichment)
- As a dry-run submit e.g. 50 CVE Descriptions, CWEs to each of the 3 LLMs to review via the chat UI in one prompt
- Ask ChatGPT4o (via Batch API) to Agree (Yes/No) with the assigned CWE (and provide a Confidence score, and rationale if not)
- Sort these by Confidence score i.e. start with the highest Confidence ones.
- Assign the same task to Gemini and Claude via APIs driven by langchain
Create a Prompt¶
Chat Interface - Table Output¶
caption_system_prompt =
You are a cybersecurity expert specializing in identifying Common Weakness Enumeration (CWE) IDs from CVE descriptions.
Your goal is is to say if you Agree with the assigned CWE ID or not.
You will be provided with a CVE ID and description amd a CWE ID that has been assigned to that CVE description.
Please provide the response in a table 'cve_id', 'CWE_ID', 'Agree'. "Rationale", Confidence' where
1. Agree: string // Yes or No
2. Rationale: string // Only if you do not Agree, provide a rationale why not
3. Confidence: string // a confidence score between 0 and 1
The table output allows copy-and-pasting by a human into a sheet.
The prompt consists of these parts:
- Role + Task: which is the same for the Chat and API interface
- Output format: which is different for the Chat and API interface
- A binary value Agree is requested
- The rationale only if there is disagreement. This saves on output tokens.
- A Confidence score to limit impacts of hallucinations, and as a way to assess and prioritize responses by confidence.
- No (Few-shot) examples are provided. Based on the results, these were not necessary.
- If Few-shot examples were required, I'd submit multiple CVEs in a single batch request (because putting the examples in each single CVE request would add a LOT of input tokens)
Batch API Interface - JSON Output¶
caption_system_prompt =
You are a cybersecurity expert specializing in identifying Common Weakness Enumeration (CWE) IDs from CVE descriptions.
Your goal is is to say if you Agree with the assigned CWE ID or not.
You will be provided with a CVE ID and description amd a CWE ID that has been assigned to that CVE description.
You will output a json object containing the following information:
{
Agree: string // Yes or No
Rationale: string // Only if you do not Agree, provide a rationale why not
Confidence: string // a confidence score between 0 and 1
}
Use JSON Mode
ChatGPT and Gemini 1.5 support JSON mode that always outputs valid JSON. Use it!
While you can prompt an LLM to output JSON, it may not always output valid JSON and you're left with a cleanup exercise (a friend of mine had that experience when they first tried this 😉)
Claude doesn't have a formal "JSON Mode" though, in my usage, it always produced valid JSON.
Tip
It is possible to submit multiple CVEs in one prompt for each batch entry i.e. similar to what is done when using the Chat interface.
- This is what is done here. 10 CVE CWE assignments are sent per batch (though the OpenAI Batch API example contains 1 entry only)
LLMs¶
Gemini 1.5 Pro API via Langchain¶
The API interface (via Langchain) was used in this example submitting multiple CVEs in one prompt.
Claude 3.5 Sonnet API via Langchain¶
Model¶
Currently: Claude 3.5 Sonnet was used as it has the best performance vs cost for Claude models.
Interface¶
Currently: Claude does not support a native Batch API interface - though Amazon Bedrock supports batching of prompts to models including Claude.
The API interface (via Langchain) was used in this example submitting multiple CVEs in one prompt.
ChatGPT4o Batch API¶
Model¶
gpt-4o
Plan¶
The Plus plan subscription was used.
Quote
There are some restrictions:
- The file can contain up to 50,000 requests.
- The file cannot be more than 100 MB in size.
Enqueued token limit reached for gpt-4o in organization XYZ. Limit: 90,000 enqueued tokens. Please try again once some in_progress batches have been completed.'
Interface¶
Batch Interface API.
The ~1800 ADP CVE-CWE pairs were split into 15 files of 100 CVE-CWE pair prompts to comfortably fit under this token limit.
- very little effort was spent to optimize the file size (number of prompts per batch), or the prompt size.
- The cost to process the ~1800 ADP CVE-CWE pairs: ~$2.
Observations¶
Leak¶
Several CVE Descriptions that include "leak" were incorrectly assigned "CWE-200 Exposure of Sensitive Information to an Unauthorized Actor".
These were actually resource leaks (memory, program objects like handles etc...), not leakage of sensitive data.
Gemini 1.5 Pro Hallucinations¶
Failure
From a sample of 30 assigned CWEs, Gemini 1.5 Pro had 3 hallucinations when asked to provide a rationale for its response (response text shown below, with hallucination in bold).
Quote
- While CWE-400 (Uncontrolled Resource Consumption) could be a potential consequence, the core issue described in the CVE is about improper handling of the Python crash handler within a chroot environment. This misconfiguration could allow an attacker to potentially escape the chroot and execute code in the context of the Apport process. A more appropriate CWE might be CWE-247 (Improper Handling of Chroot Environments) or CWE-22 (Improper Limitation of a Pathname to a Restricted Directory ('Path Traversal')).
- CWE-247: DEPRECATED: Reliance on DNS Lookups in a Security Decision
- CWE-243: Creation of chroot Jail Without Changing Working Directory is the closest to "Improper Handling of Chroot Environments"
- The assigned CWE-436 (Unspecified Encoding or Escaping of Output) doesn't fit well. The description argues that the plugin itself doesn't handle file uploads, making it a matter of what WordPress allows to be uploaded. If the core WordPress installation doesn't prevent polyglot files, it's not directly the plugin's fault. A more suitable CWE might be CWE-284 (Improper Access Control) if the plugin fails to restrict access to already uploaded polyglot files, allowing unauthorized viewing or download.
- CWE-116 is the correct CWE: CWE-116: Improper Encoding or Escaping of Output
- While CWE-57 (Relative Path Traversal) could be a factor in exploiting this vulnerability, the description more directly aligns with CWE-664: Improper Control of File Deletion or Renaming Operations. The vulnerability allows attackers to delete arbitrary files, which is the core characteristic of CWE-664. Relative path traversal might be a means to reach different files, but the primary issue is the improper control over file deletion.
- CWE-664 correct title is CWE-664: Improper Control of a Resource Through its Lifetime
Tip
While Gemini 1.5 Pro is the backend for NotebookLM, no hallucinations were detected in NotebookLM (the benefit of a source-grounded closed system).
NotebookLM¶
NotebookLM works very well for suggesting a relevant CWE for a given CVE Description (or reviewing an assigned CWE)
- It suggests related CVEs to support the CWE it suggests (sometimes prompting is required). These CVEs are part of the "Observed Examples" CVEs that are listed under a CWE in the CWE standard.
- The numbered grey circles in the diagram below are links to references from the CWE standard.
 CVE-2024-35059
CVE-2024-35059
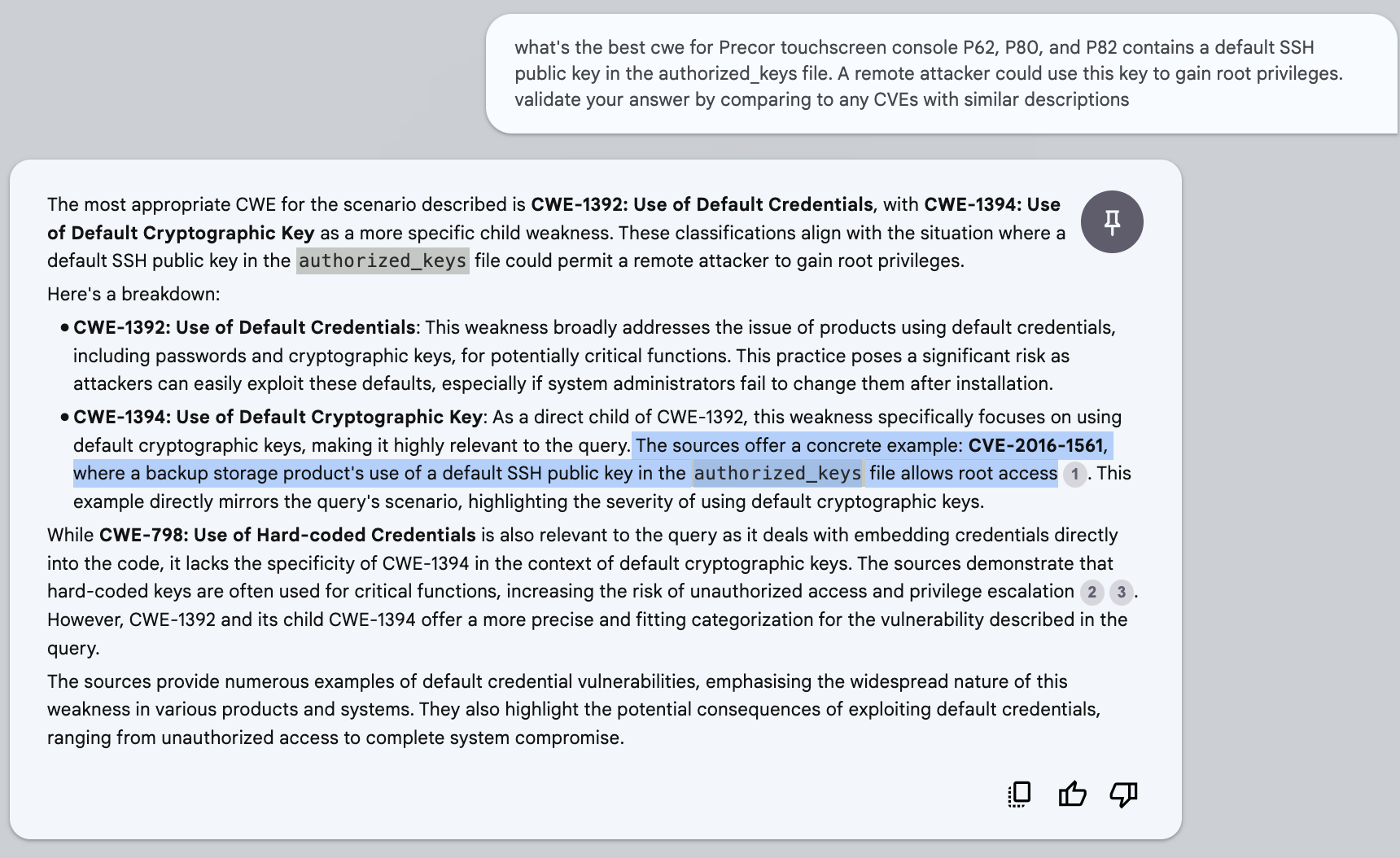 CVE-2023-49224
CVE-2023-49224
Note
The NotebookLM prompts above are deliberately not applying prompt engineering principles to show that NotebookLM still provides a useful response.
Refinements¶
Note: Some refinements are possible, but were not implemented in this first pass to minimize Time-To-Value
- The full CWE standard was used here for illustration purposes (and to take on the harder problem of a large specification)
- A subset of CWEs could be used if that is desired.
- In practice, several hundred CWEs are assigned to CVEs.
- Remove the 25 "DEPRECATED:" entries
- The text from the references in the CVE "References to Advisories, Solutions, and Tools" was not retrieved and fed to the LLM as part of the CVE Description for CWE review or assignment.
- These references were reviewed manually (for the consensus of incorrect CWE assignments)
- In some cases, this has additional text available that can inform the CWE assignment beyond the CVE Description alone
- It is relatively easy to retrieve this content automatically but this content varies significantly by type (text, image, pdf), quality, structure.
- Separately, it is common that these links break because the original website or post is removed, or it's not in the latest version in Github,... - so it would be useful to have the extracted text at the time of CWE assignment.
- Additional known good CVE descriptions and CWE assignments could be incorporated into the corpus, to augment the limited CVE observed examples that are part of the CWE standard.
- Reducing the set of CWEs to the desired population, or providing guidance in the prompt on what CWEs to use (e.g. "don't use CWE's marked as Discouraged")
- As I was interested in comparing LLM responses, I did not optimize the LLM usage (all LLMs were fed all CVE-CWEs)
- This can be done in several ways e.g.
- Ask each LLM in turn to review the previous assessments by LLMs
- Sampling
- This can be done in several ways e.g.
Takeaways¶
Takeaways
-
The value of CVE data depends on its quality.
- For all published CVEs to date, the quality of CWEs assigned is questionable.
- A large part of that is that humans can't grok ~~1000 CWEs. LLMs can.
-
Using LLMs to suggest or validate CWEs can reduce the manual effort and error in CWE assignment.
- LLMs can validate CWEs at scale e.g. using Batch mode, or multiple CVEs per prompt, or both.
- LLMs perform well at this task and, given they can be automated, can augment the human manual effort, and improve the quality of assigned CWEs.
- Langchain makes it easier to have generic code that works across multiple LLMs.
- LLM JSON Mode should be used where possible to reduce bad JSON output and subsequent cleanup.
- Based on a manual review of the subset where all 3 LLMs disagreed with the CWE assignment, > 75% of these CWEs were incorrect (and a report with these was submitted to CISA Vulnrichment)
- I did not dig into the subset where 2 of 3 LLMs disagreed.
- Using LLMs to suggest or validate CWEs can reduce the manual effort and error in CWE assignment.
- A closed-system that is grounded on the CWE standard only e.g. NotebookLM, performs very well for assigning CWEs, or reviewing assigned CWEs (though it does not have an API so can't do this at scale), and no hallucinations were observed.