AI Coding Leaderboards¶
Overview
This page is a list of benchmarks for LLMs that are used to help with coding.
It covers both Coding Assistants and Autonomous Coding Agents
Leaderboards¶
| Leaderboard | Category | Tasks | Metrics |
|---|---|---|---|
| Aider LLM Leaderboards | Coding Assistant | 225 Exercism exercises across C++, Go, Java, JavaScript, Python, Rust | Two-pass pass rates; cost per run; edit correctness |
| EvalPlus Leaderboard | Coding Assistant | HumanEval+ (164 hand-verified Python); MBPP+ (399 sanitized Python) | pass@1 (greedy); extended efficiency via EvalPerf |
| TabbyML Coding LLMs Leaderboard | Coding Assistant | Amazon CCEval next-line tasks in Python, JS, Go… | Next-line accuracy (exact-match of very next line) |
| MHPP Leaderboard | Coding Assistant | 210 “Mostly Hard” multi-step Python problems | pass@1 (greedy); sampling (T=0.7, 100 runs) |
| Copilot Arena | Coding Assistant | Paired autocomplete & inline-editing comparisons | ELO-style rankings from user votes |
| WebDev Arena Leaderboard | Coding Assistant | Real-time web development challenges between models | Win rate; task completion; user voting |
| SWE-bench | Autonomous Agent | 2,294 real-world “Fail-to-Pass” GitHub issues from 12 Python repos | % of issues resolved |
| HAL (Holistic Agent Leaderboard) | Autonomous Agent | 13 benchmarks (e.g., SWE-bench Verified, USACO, Cybench, TAU-bench) across many domains | Cost-controlled evaluations; success rates; Pareto fronts |
| TBench | Autonomous Agent | Terminal-based complex tasks in realistic environments | Task success rate; command accuracy; time-to-completion |
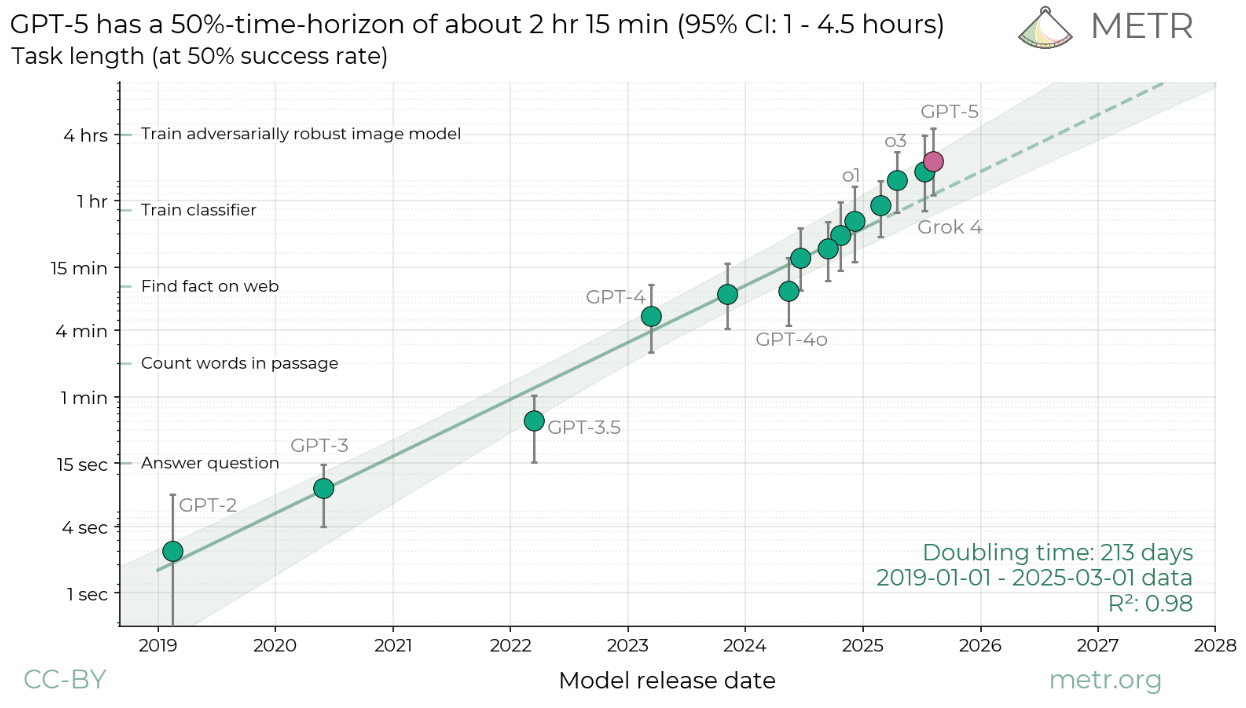
Measuring AI Ability to Complete Long Tasks¶
Tip
The length of tasks (measured by how long they take human professionals) that generalist autonomous frontier model agents can complete with 50% reliability has been doubling approximately every 7 months for the last 6 years
Measuring AI Ability to Complete Long Tasks
Other Evaluations¶
In addition to leaderboards, it is useful to read about other evaluations and experiments e.g.
- How far can we push AI autonomy in code generation?, Birgitta Böckeler ThoughtWorks, August 2025
Takeaways¶
Key Takeaways
Leaderboards are a good way to quantitatively and objectively compare solutions.
Comparison across multiple metrics and leaderboards avoids solutions that overfit to a benchmark.