Software Engineering 1.0 Redux Security¶
Overview
This section covers the Core Review Security touchpoint.
We touched on this point earlier in NotebookLM Secure Code.
Software Security Touchpoints¶
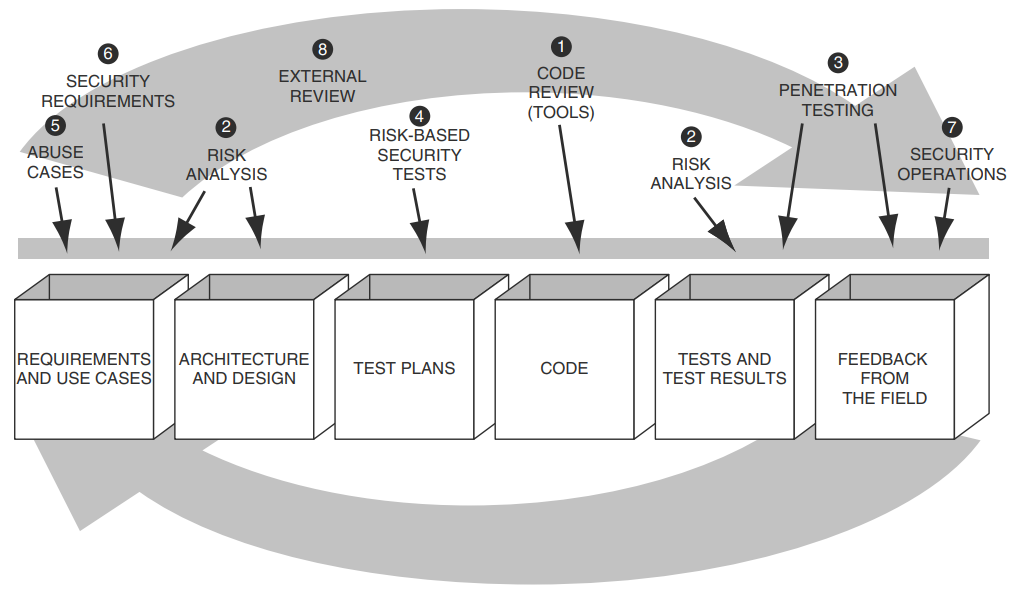 Image from Secure Programming with Static Analysis by Brian Chess, Jacob West
Image from Secure Programming with Static Analysis by Brian Chess, Jacob West
Finding Defects in Source Code¶
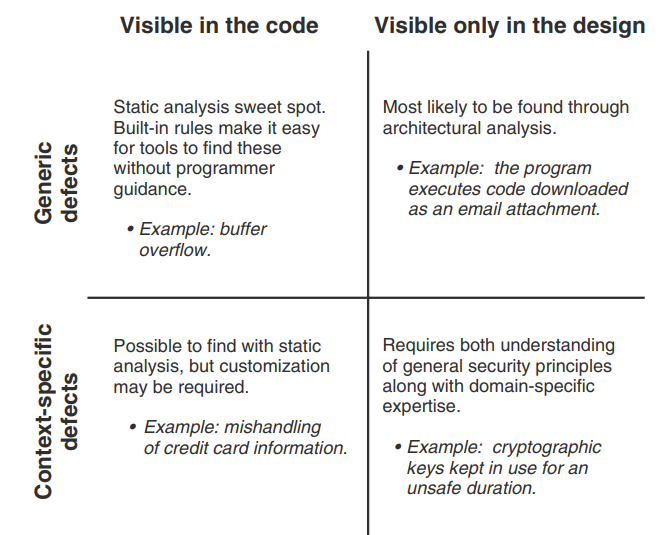 Image from Secure Programming with Static Analysis by Brian Chess, Jacob West
Image from Secure Programming with Static Analysis by Brian Chess, Jacob West
The best way to find a particular defect depends on whether it is generic or context specific, and whether it is visible in the code or only in the design.
LLMs can compliment the Static analysis sweetspot (Generic defects - Visible in the code)
- "SAST tools often rely on predefined patterns and rules, which can result in high false-positive rates and an inability to detect novel or context-dependent vulnerabilities" per ref.
- Additional context can be given to LLMs to improve their performance e.g. vulnerability reports on similar code LSAST: Enhancing Cybersecurity through LLM-supported Static Application Security Testing
How to use LLMs and SAST Tools Together¶
LLMs can be used with Code Analysis Tools in different ways:
- Create a formatted report of findings:
- this is more an editorial activity - not code analysis
- Utilising LLMs for False Positive Mitigation (FPM) on SAST Warnings:
- Traditional SAST tools often generate a high volume of false positive alerts, which can be time-consuming and resource-intensive for developers to manually review.
- LLMs can be integrated to automate this false positive mitigation process
- Direct Integration of SAST Results with LLMs:
- SAST tools provide initial insights into known vulnerabilities based on predefined rules and patterns. Their findings, including details like CWE IDs and line numbers, can be formatted and directly incorporated into the prompts provided to LLMs alongside the target code.
- This approach, referred to as "RAW LSAST," has been shown to significantly enhance the LLM’s ability to detect vulnerabilities that static scanners alone might miss, thereby improving overall detection accuracy
- Independently look for issues
- e.g. using an analysis of CPGs.
- Actively exercise the code by creating or guiding test cases.
Quote
While traditional tools like Bandit are valuable, our results show that LLMs provide a complementary advantage by analyzing fragmented and non-compilable code and detecting complex vulnerability patterns that existing tools may miss. Additionally, the ability of LLMs to generate security tests adds a useful layer of verification, potentially enhancing the accuracy of vulnerability assessments.
Quote
Our findings indicate that SAST tools exhibit low vulnerability detection ratios while maintaining a low marked function ratio, akin to a low false positive rate. In contrast, LLMs demonstrate high vulnerability detection ratios but are accompanied by elevated marked function ratios (akin to high false positive rates). Through ensemble approaches, we demonstrate that combining SAST tools and LLMs mitigates their respective limitations, resulting in improved overall vulnerability detection performance.
Quote
Analysis reveals that the optimal approaches differ across programming languages. The best choice will depend on the user’s acceptance of the trade-off between detection ratios and marked function ratios.
Quote
The reasoning-oriented models consistently produced fewer false positives, suggesting that their internal steps for “validating” potential vulnerabilities lead to more precise outcomes.
CASTLE: Benchmarking Dataset for Static Code Analyzers and LLMs towards CWE Detection
Code Context¶
A challenge with using LLMs is to get the precise and complete code context to the LLM as described in Utilizing Precise and Complete Code Context to Guide LLM in Automatic False Positive Mitigation. They developed a tool to extract this code context.
Quote
- First, we propose a line-level precise code slicer eCPG-Slicer. It constructs an extended Code Property Graph (eCPG) and then extracts line-level code context related to the warning within the given files.
- Second, we propose a linear complexity algorithm, FARF, which is used to identify source files that have dependencies related to a warning, enabling the slicer to extract the complete code context.
- Third, we integrate our eCPG-Slicer and FARF algorithm into our LLM4FPM framework. LLM4FPM can efficiently drive LLMs to give judgements for a given warning generated by SAST tools.
Note
The source code for these does not appear to be publicly available. But Joern is an open source solution used for such purposes.
Quote
A code property graph of a program is a graph representation of the program obtained by merging its abstract syntax trees (AST), control-flow graphs (CFG) and program dependence graphs (PDG) at statement and predicate nodes. https://en.wikipedia.org/wiki/Code_property_graph
Quote
Joern is a platform for analyzing source code, bytecode, and binary executables. It generates code property graphs (CPGs), a graph representation of code for cross-language code analysis. Code property graphs are stored in a custom graph database. https://github.com/joernio/joern
Quote
- Precise Code Context. The extracted code snippet should focus on control flows and data flows relevant to the warning, capturing the precise code context while omitting unnecessary parts that might distract the LLM and lead to incorrect or ambiguous conclusions.
- Complete Code Context. The analysis should account for key information often missing from bug reports, such as references to global variables or invoked functions located in other files. Without this, the extracted context remains incomplete.
- Correct Conclusions. After obtaining precise and complete code context, there is an opportunity to more effectively guide the LLM to make accurate judgments on bug reports from SAST tools.
Utilizing Precise and Complete Code Context to Guide LLM in Automatic False Positive Mitigation
References¶
- AI Cyber Challenge (2025). AIxCC Open Source Archive.
- Official archive providing open-source access to all seven finalist Cyber Reasoning Systems (CRSs), released to accelerate adoption of AIxCC-developed technology in cybersecurity and software development. https://archive.aicyberchallenge.com
- See DARPA AI Cyber Challenge Tools Comparison Report
- Brian, C., & West, J. (2007). Secure programming with static analysis. Addison-Wesley.
- McGraw, G. (2006). Software security: Building security in. Addison-Wesley.
- Zhang, Y., Li, Y., Wang, T., et al. (2025). Towards effective complementary security analysis using large language models. arXiv preprint. https://arxiv.org/html/2506.16899v1
- Xu, H., Chen, M., & Zhou, L. (2025). Leveraging large language models for command injection vulnerability analysis in Python: An empirical study on popular open-source projects. arXiv preprint. https://arxiv.org/html/2505.15088v1
- Li, J., Wang, P., & Huang, K. (2025). LLM vs. SAST: A technical analysis on detecting coding bugs of GPT4-Advanced Data Analysis. arXiv preprint. https://arxiv.org/html/2506.15212v1
- Müller, T., & Kim, D. (2024). Comparison of static application security testing tools and large language models for repo-level vulnerability detection. arXiv preprint. https://arxiv.org/abs/2407.16235
- Shen, R., & Zhao, F. (2024). LSAST: Enhancing cybersecurity through LLM-supported static application security testing. arXiv preprint. https://arxiv.org/html/2409.15735v2
- Kumar, V., & Singh, A. (2025). CASTLE: Benchmarking dataset for static code analyzers and LLMs towards CWE detection. arXiv preprint. https://arxiv.org/html/2503.09433v1
- Li, C., & Zhang, H. (2024). Source code vulnerability detection: Combining code language models and code property graphs. arXiv preprint. https://arxiv.org/html/2404.14719v1
- Kolla, H. (2024). SecLint: An agentic code vulnerability detection tool using RAG. Substack. https://harishkolla.substack.com/p/seclint-an-agentic-code-vulnerability
- Gross, C. (2025, August). Slice: SAST + LLM interprocedural context extractor. noperator.dev. https://noperator.dev/posts/slice/
- Google Security Team. (2024). Google Big Sleep AI tool finds critical Chrome vulnerability. LinkedIn. https://lnkd.in/gSkA3kRC
- Heelan, S. (2024). Using o3 to discover a remote zeroday vulnerability in the Linux kernel’s SMB implementation. LinkedIn. https://lnkd.in/gHZqC_k3
- Wang, Z., Shi, T., Song, D., et al. (2024). CyberGym: Evaluating AI agents' cybersecurity capabilities with real-world vulnerabilities at scale. UC Berkeley. https://www.cybergym.io/
- Gaucher, R., Ermilov, V., & [Author], A. (2024). Finding vulnerabilities in modern web apps using Claude Code and OpenAI Codex. LinkedIn. https://lnkd.in/gGWaZzHk
- Li, Z., Li, Y., Wang, T., et al. (2024). IRIS: LLM-assisted static analysis for detecting security vulnerabilities. arXiv preprint. https://arxiv.org/abs/2405.17238
- (2025). Harnessing the power of LLMs for vulnerability detection. arXiv preprint. https://arxiv.org/html/2504.18423v1
- (2025). Advancing software vulnerability detection with reasoning-enabled large language models. Applied Sciences. https://www.mdpi.com/2076-3417/15/12/6651
- Khare, A., Dutta, S., Li, Z., Solko-Breslin, A., Alur, R., & Naik, M. (2023). Understanding the effectiveness of large language models in detecting security vulnerabilities. arXiv preprint. https://arxiv.org/abs/2311.16169
- Yang, Y., Xu, B., Gao, X., & Sun, H. (2025). Context-enhanced vulnerability detection based on large language models. arXiv preprint. https://arxiv.org/abs/2504.16877
- Kaniewski, S., Schmidt, F., Enzweiler, M., Menth, M., & Heer, T. (2025). A systematic literature review on detecting software vulnerabilities with large language models. arXiv preprint. https://arxiv.org/abs/2507.22659
- See Awesome-LLM4SVD for the surveyed papers, taxonomy, datasets: https://github.com/hs-esslingen-it-security/Awesome-LLM4SVD
- Sheng, Z., Chen, Z., Gu, S., Huang, H., Gu, G., & Huang, J. (2025). LLMs in software security: A survey of vulnerability detection techniques and insights. arXiv preprint. https://arxiv.org/abs/2502.07049
- Klieber, W., & Flynn, L. (2024, October 7). Evaluating static analysis alerts with LLMs. Cybersecurity Engineering, SEI blog. https://www.sei.cmu.edu/blog/evaluating-static-analysis-alerts-with-llms/
- Ferro, A. (2024). Beyond static analysis: AI-powered vulnerability detection. Medium. https://medium.com/engaging-innovation/beyond-static-analysis-ai-powered-vulnerability-detection-690ff4e1f94c
- (2024). Research on LLM for vulnerability detection – Fernweh. Blog post. https://blog.wohin.me/posts/recent-llm-for-vuln-detection/
- Nice summary of 18 studies on LLM for vulnerability detection
In Depth Articles on Tools¶
- Hakimian, P. (2025, October 31). WTF is … AI-Native SAST? Hackerman’s Hacking Tutorials. https://parsiya.net/blog/wtf-is-ai-native-sast/.
- scabench-org. (2025). Hound: Language-agnostic AI auditor that autonomously builds and refines adaptive knowledge graphs for deep, iterative code reasoning. GitHub repository. https://github.com/scabench-org/hound.
- Karger, R. (2024, November 1). How ZeroPath Works: Technical deep-dive into ZeroPath’s SAST methodology—from AST generation to AI-powered vulnerability discovery and automated patch generation. ZeroPath Blog. https://zeropath.com/blog/how-zeropath-works.
- Rogers, J. (2025, September 18). Hacking with AI SASTs: An overview of “AI Security Engineers” / “LLM Security Scanners” for Penetration Testers and Security Teams. Joshua.Hu — Joshua Rogers’ Scribbles. https://joshua.hu/llm-engineer-review-sast-security-ai-tools-pentesters.